Problem Faced
Problem 1
Disorganized Table Structure:
The existing table layout lacked clear organization, making it difficult for users to understand and interpret the extracted data quickly.
This resulted in poor readability and hindered efficient data review.
Problem 2
Unintuitive Extracted Fields Area:
The interface for reviewing, validating, and editing extracted fields was not user-friendly.
Users struggled to navigate and manipulate the data, leading to a frustrating and error-prone experience.
The visual design was not cohesive.
Problem 3
Challenges with Complex Table Extraction:
The system struggled to accurately and efficiently extract data from complex document tables.
This resulted in incomplete or incorrect data, hindering users' ability to rely on the extracted information.
The current interface was not intuitive.
An Overview
Objectives
Instead of diving into complex persona development, we focused on understanding the core user needs. We discovered that users prioritized clarity, efficiency, and ease of use.
The key insight: users needed a streamlined and intuitive interface that simplified the complex task of table data extraction.
We focused on understanding the core issues users had with the existing table, and what they expected from it.
Solution: 1
Optimizing the extracted fields area
I led the design process, employing an iterative approach that emphasized user feedback and technical collaboration.
Catering to colour blind users
Optimizing the extracted fields area
Involvement of colours in the extracted data: Colours were chosen such that it can be differentiated by colour blind people also.
This involved having competitive research were I checked the competitor products like Google vision, Nanonets etc

Solution: 2
Optimizing the extracted Table area
I aimed to transform the table structure, ensuring exceptional clarity and intuitive organization, empowering users to effortlessly interpret and utilize extracted data.
To improve visibility and differentiation within the data, we incorporated zebra lines into the table design. This enhancement, based on user feedback during testing, significantly aided in data scanning and reduced visual fatigue.
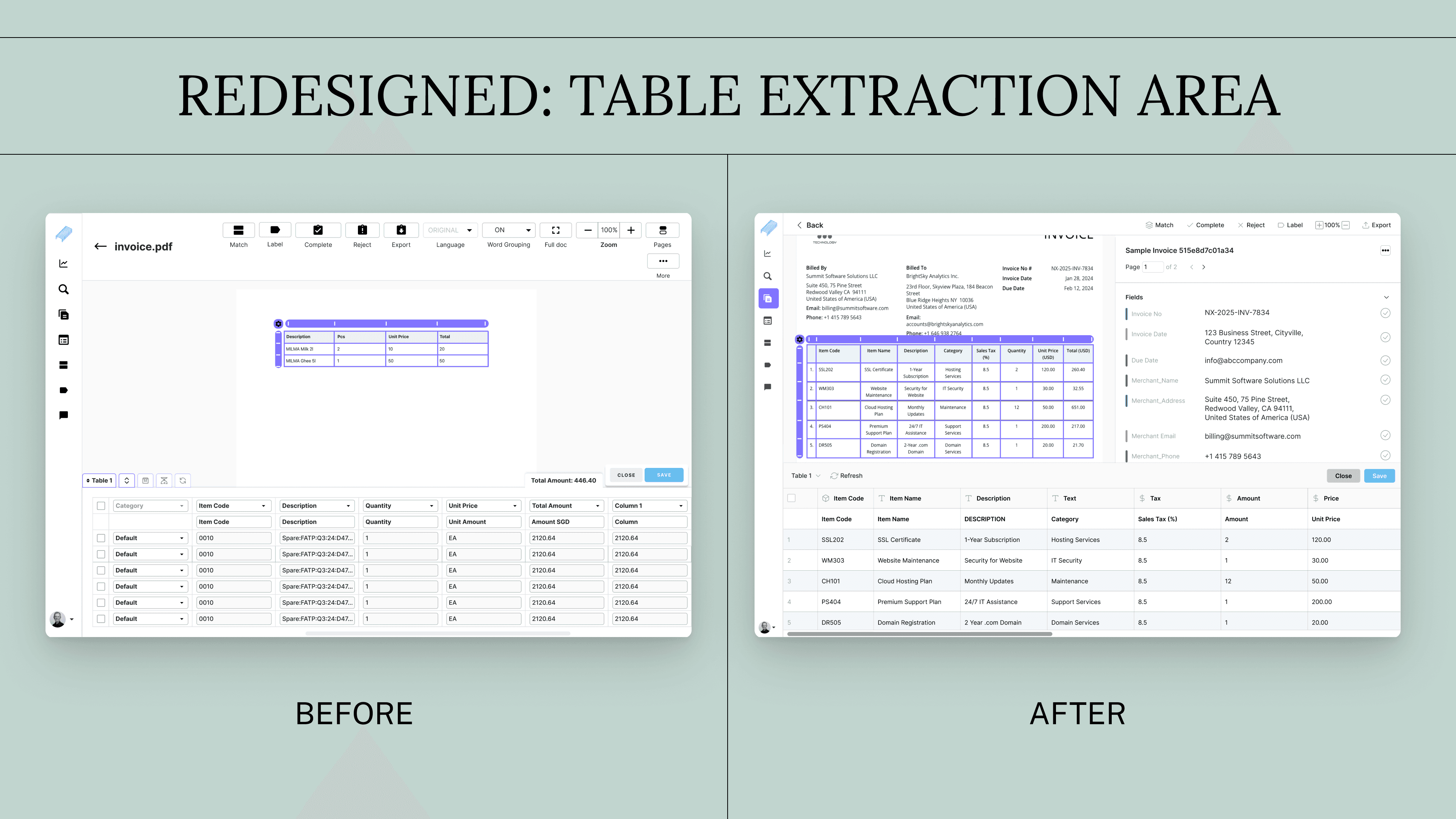
Solution: 3
Data exctraction from complex tables
I aimed to transform the table structure, ensuring exceptional clarity and intuitive organization, empowering users to effortlessly interpret and utilize extracted data.
To improve visibility and differentiation within the data, we incorporated zebra lines into the table design. This enhancement, based on user feedback during testing, significantly aided in data scanning and reduced visual fatigue.
Core Problems
Barriers to Efficient Data Extraction
Merged Cell Misalignment:
Data within merged cells was frequently misaligned or split incorrectly during extraction.
This necessitated time-consuming manual corrections, causing user frustration and reduced efficiency.
Multi-Level Header Identification Errors:
The system failed to accurately identify multi-level (grouped) headers.
This led to misinterpretations of data and hindered accurate analysis.
Inconsistent Table Structure Issues:
Tables with missing rows, empty cells, or inconsistent column spans resulted in data extraction errors.
This unpredictability forced users to manually verify all extracted data, undermining trust in the system.
Understanding AI Capabilities
Discussion with AI/ML team
The AI/ML team provided invaluable insights into how the system processed merged cells, multi-level headers, and inconsistent table structures. This allowed me to grasp the specific challenges they faced in accurately extracting data from these complex formats.
Based on these discussions, I developed two potential solutions: One focused on providing users with more granular control over header definitions, and the other explored a more automated approach that leveraged AI to intelligently interpret table structures.
A crucial insight emerged from discussions with the backend engineers: 'If you can make the AI understand about the headers/columns you needed in a table then the population of line items will be 97% accurate.' This highlighted the importance of providing the AI with clear and accurate header information.
The Design
Population of headers and line items
Implemented a visual selection tool for direct header highlighting in the table preview.
Added real-time visual feedback to confirm header selections and relationships.
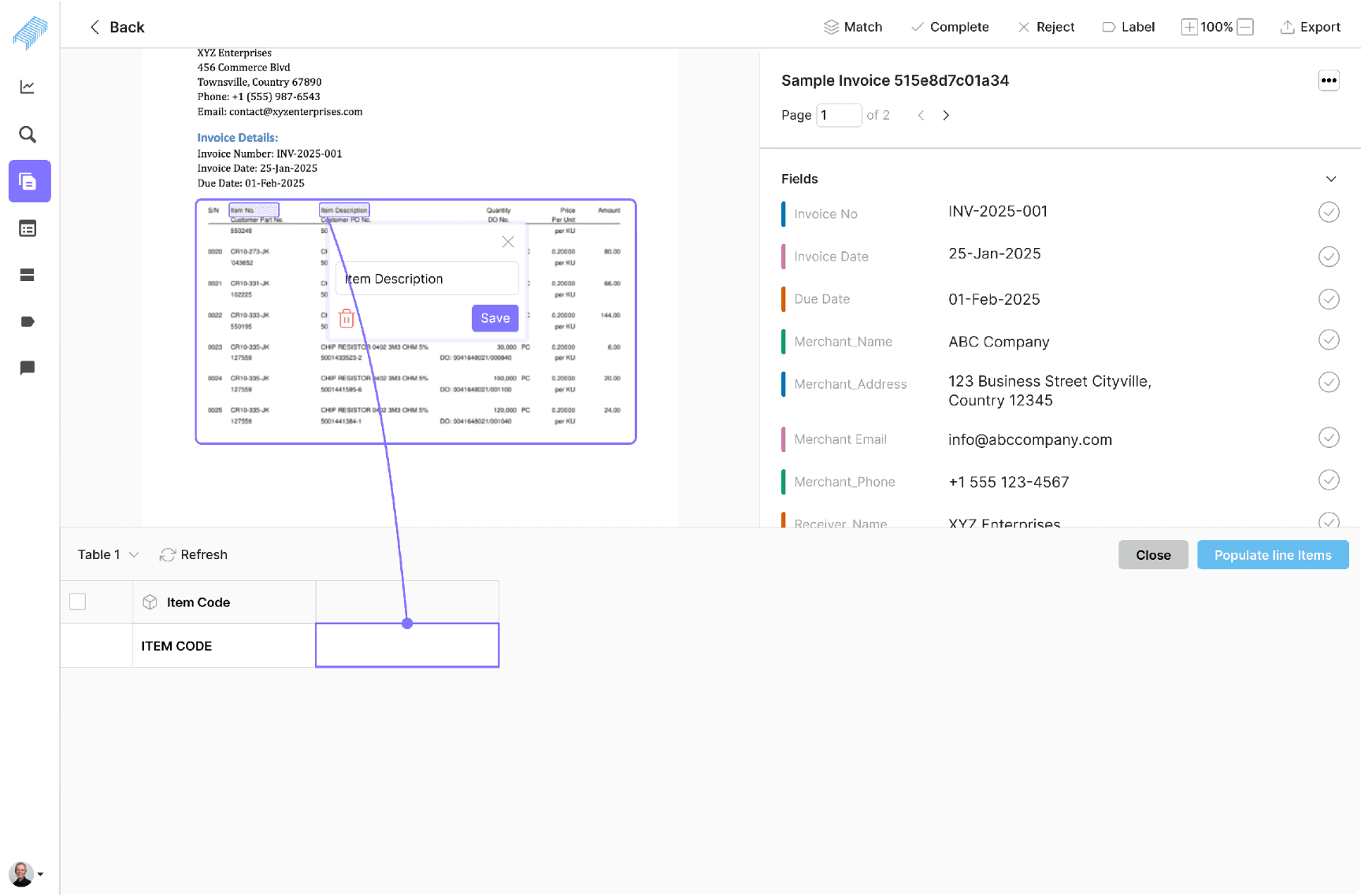


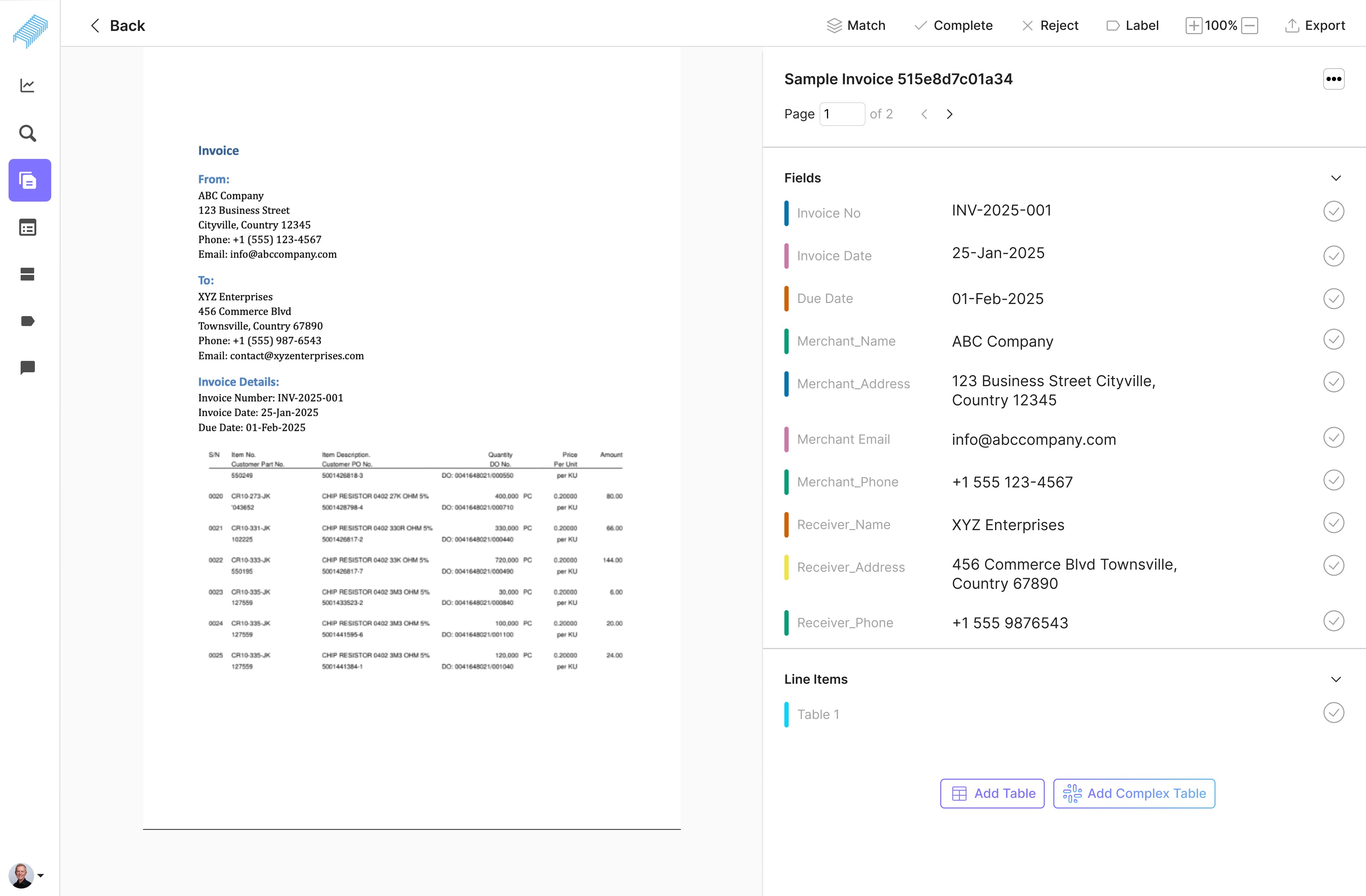
The impact
Impact of the redesign
Improved Workflow:
50% reduction in time spent correcting errors.
Fewer manual steps, leading to a faster table extraction process.
Higher Data Accuracy:
Accuracy increased by 30-40%.
Improved handling of irregular layouts, merged cells, and multi-level headers.
Increased Productivity:
Teams reported a 25-40% boost in overall productivity.
Due to the faster extraction process.
Scalability for Advanced Use Cases:
Redesigned system supports more diverse document types.
Suitable for all industries.
Better Adaptability for Complex Structures:
Smart auto-detection handles edge cases.
Successfully manages irregular column spans, empty cells, and multi-level headers.







